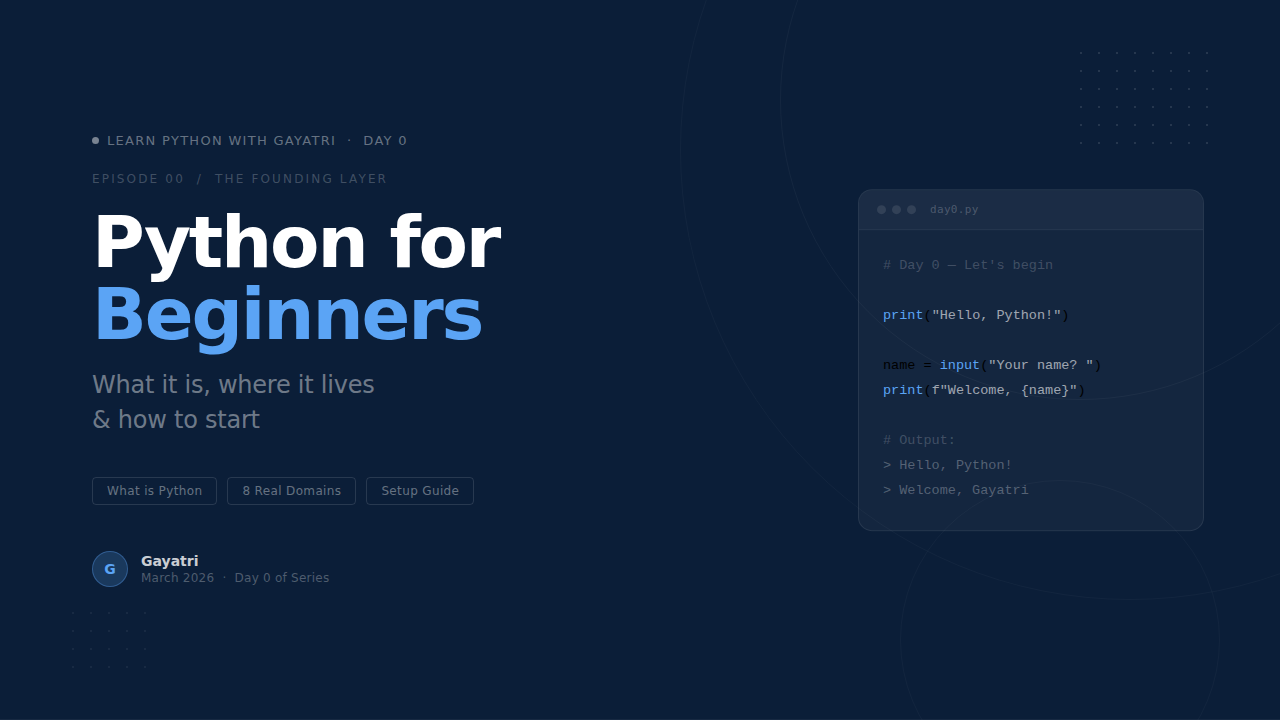
DevOps
PostgreSQL Performance Tuning Deep Dive | Stop Restarting
Stop using restarts as a crutch. Master PostgreSQL performance tuning by optimizing shared_buffers, managing transaction locks, and applying postgresql.conf changes via SIGHUP …