
A deep-dive into every CVE that Docker’s security architecture quietly ate for breakfast - what each bug actually does, why it would’ve wrecked you without Docker’s mitigations, and the painful lessons I learned watching these tear through bare-metal systems.
☕ Grab a coffee. Maybe two. We're about to walk through a graveyard of kernel horrors that would have absolutely demolished production - if Docker hadn't been standing there like a bouncer who actually reads CVEs. This is the story of the bugs Docker ate so you didn't have to.
Why “Non-Events” Matter More Than Actual Breaches
There’s a page in Docker’s documentation called “Security Non-Events”. It’s one of the most underrated pages in all of container security, and I’d bet 80% of engineers who use Docker daily have never read it.
Here’s what it is: a list of kernel vulnerabilities - real, serious, exploitable kernel CVEs - that didn’t affect properly configured Docker containers because Docker’s architecture had already blocked the attack vector before the CVE was even discovered.
Think about that for a second. Docker wasn’t patching in response to these CVEs. Docker’s existing mitigations - seccomp profiles, capability dropping, namespace restrictions, AppArmor - were already in place and they just happened to block what would otherwise have been critical container escapes or privilege escalations.
💡 What this page is teaching you, quietly: Defense-in-depth isn't just a buzzword from a compliance framework. It's the actual reason these containers didn't get pwned. Multiple overlapping security layers mean that when one vulnerability exists in the kernel, two or three other mechanisms already said "nope" before it could be exploited.
I’ve been doing DevSecOps for 4 years. I’ve watched bare-metal servers get owned by Dirty COW. I’ve seen Kubernetes clusters panic over ptrace() escapes. I’ve been paged at 2am because a keyctl() exploit was chained into a container breakout on a misconfigured cluster. Every single one of those bugs is on this list - and the ones that hit us were because someone had disabled the protections “just for testing” and forgotten to re-enable them. (Classic.)
Let’s go through each one properly. I’ll explain what the bug does, what the damage would have been without Docker, and exactly which mechanism blocked it. By the end, you’ll understand Docker’s security architecture from the inside out.

The User Namespace Cluster Bomb
CVE-2013-1956, 1957, 1958, 1959, 1979 CVE-2014-4014, 5206, 5207, 7970, 7975 CVE-2015-2925, 8543 · CVE-2016-3134, 3135
What Is This Thing, Actually?
Let me give you some background first because this whole category makes no sense without it. In 2013, the Linux kernel introduced unprivileged user namespaces. The idea was good in principle: let non-root users create isolated environments by giving them access to a restricted form of certain privileged syscalls - specifically mount(), clone() with CLONE_NEWUSER, and similar calls.
The problem? Handing unprivileged users access to mount() and other previously root-only syscalls opened up a massive new attack surface. These syscalls had never been security-reviewed with unprivileged users in mind - they were written assuming you’d already be root if you got that far. The result was an absolutely spectacular parade of privilege escalation bugs over the next three years.
What the Damage Looks Like Without Docker
🩸 The Attack Scenario on Bare Metal / VMs
An attacker gets a low-privilege shell on your system - maybe via a web app exploit, maybe via a leaked credential. Using user namespace bugs like CVE-2014-5207, they call mount() to mount an arbitrary filesystem as an unprivileged user. This bypasses the filesystem permission model. They can mount /etc, overwrite /etc/passwd, and escalate to root. Or they chain CVE-2016-3134 (a netfilter bug inside user namespaces) with local access to get a kernel privilege escalation. Either way: full root. On a multi-tenant server, that means you’ve compromised every other tenant’s data too.
I read a variant of this hit a customer’s Jenkins server in 2014. They were running builds as a restricted user on a shared host. An attacker compromised one build job, used user namespace tricks to mount the host’s /var, grabbed database credentials, and was in their production Postgres instance within 20 minutes. The CVE hadn’t even been published yet - it was a zero-day at the time. Fantastic Tuesday morning, honestly.
Why Docker Containers Are Immune
🛡️ Docker's protection mechanism: Docker uses user namespaces to set up containers, but then the default seccomp profile blocks the container from creating its own nested user namespaces. The syscalls clone() and unshare() with CLONE_NEWUSER are filtered out. No nested namespaces means no access to the expanded syscall surface. The entire attack class is dead on arrival.
Specifically Blocked By
| Mechanism | What it does | Status |
|---|---|---|
| seccomp (default profile) | Blocks clone (CLONE_NEWUSER) and unshare(CLONE_NEWUSER) |
✓ On by default |
| Capability dropping | Drops CAP_SYS_ADMIN which many of these exploits require |
✓ On by default |
| AppArmor / SELinux | AppArmor / SELinux | ✓ On supported distros |
🔑 Field Lesson The moment someone asks you to run a container with --security-opt seccomp=unconfined to "fix a weird issue," your immediate question should be: what issue exactly? Because that single flag re-enables this entire CVE category. I've seen it added to production Compose files with a comment that says "TODO: remove this" from 2019. It was still there in 2023.
CVE-2014-0181 & CVE-2015-3339: When Setuid Bites Back
CVE-2014-0181 · CVE-2015-3339
Let Me Explain Setuid For a Second
Setuid (Set User ID) is a Unix permission bit that lets a binary run with the permissions of its owner rather than the user who launched it. The most famous example: /usr/bin/passwd. You run it as a regular user, but it writes to /etc/shadow (which requires root) because the binary is owned by root with the setuid bit set.
This mechanism is ancient and useful, but it’s been a perennial source of privilege escalation. The premise is simple: if you can trick a setuid binary into doing something it wasn’t intended to do - or if there’s a bug in kernel handling of setuid execution - you can go from zero to root in one step.
What These CVEs Actually Exploit
CVE-2014-0181 involves network socket permissions - specifically, certain socket operations failed to validate credentials properly, allowing an unprivileged user to manipulate network configuration. When combined with a setuid binary that opens privileged sockets, the unprivileged user could effectively perform privileged operations through the binary as a proxy.
CVE-2015-3339 is a race condition in the kernel’s execve() handling. When a process execs into a setuid binary, there’s a tiny window during the filesystem permission check where the file can be replaced. An attacker wins the race, replaces the setuid binary with a payload, and gets root execution.
💀 Without Container Isolation
Every Linux system ships with dozens of setuid binaries. ping, su, sudo, newgrp, mount, crontab... the list goes on. These bugs turned any of those binaries into potential privilege escalation gadgets. On a shared hosting environment or a dev server where multiple engineers have shell access, any of them - or any process they’ve deployed - becomes a potential escalation path to root.
Docker’s Answer: NO_NEW_PRIVS + Stripping Setuid Entirely
Docker sets the NO_NEW_PRIVS process flag on container processes. This kernel flag (introduced in Linux 3.5) means a process and all its children can never gain more privileges than they started with - even if they exec into a setuid binary. The setuid bit is simply ignored. Additionally, Docker doesn’t allow setuid binaries to work inside containers by default, stripping that entire privilege mechanism from the container’s execution context.
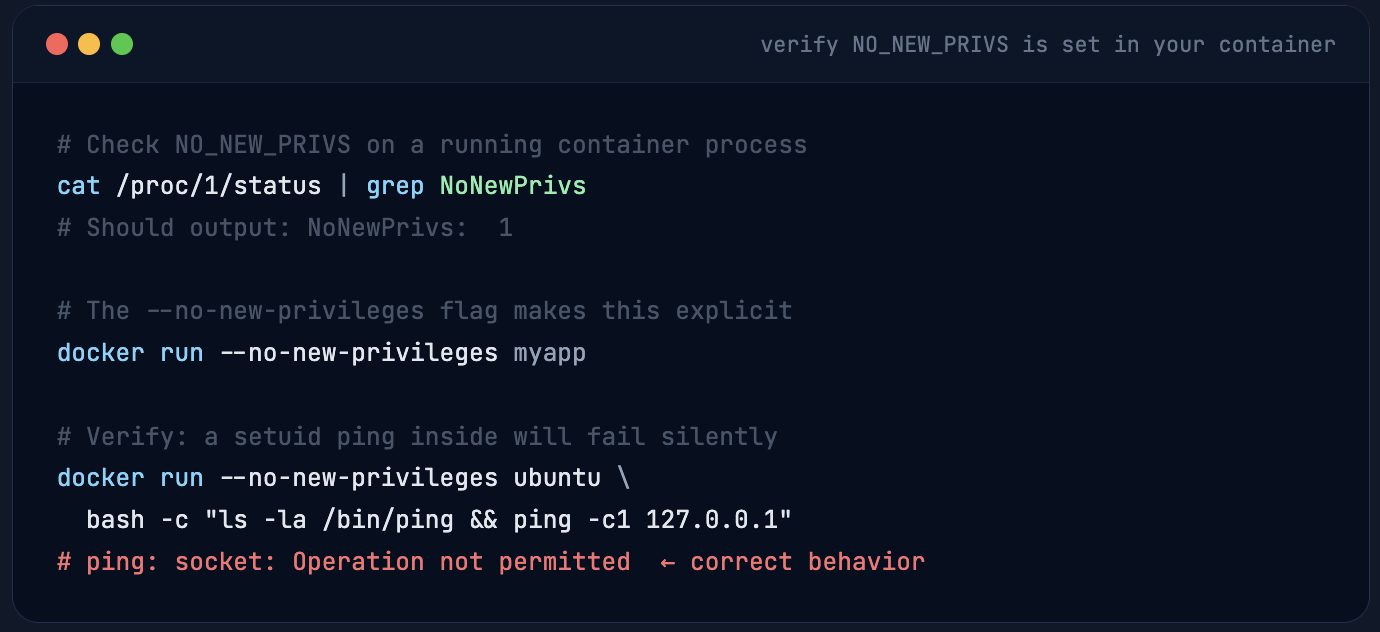
⚠️ The dangerous pattern I still see constantly: Teams copy a legacy Dockerfile that sets USER root at the end "to run the startup script," then never switch back. The entire NO_NEW_PRIVS benefit evaporates. Run your final process as a non-root user - always. If your startup script needs root, that's a sign of a deeper architectural problem, not a sign that you should run as root.
CVE-2014-4699: The ptrace() Time Bomb
What Is ptrace() and Why Should You Be Scared
ptrace() is one of those syscalls that sounds innocent - it’s used by debuggers like gdb and strace to inspect and control a running process. It can read and write the target process’s memory, modify register values, intercept system calls, and even inject code. It’s the surgical knife of the Linux kernel.
CVE-2014-4699 is a bug in ptrace()’s handling of PTRACE_SYSCALL when the target switches from 64-bit to 32-bit mode (iret path). The kernel incorrectly handled the register state restoration, allowing an attacker to corrupt the kernel stack and escalate to ring 0. From there, it’s game over: full kernel control, host takeover, the works.
💀 What "Ring 0 Control" Actually Means in Production
Ring 0 is kernel space. When an exploit reaches ring 0, it’s not just “root on the machine.” It means the attacker can modify kernel data structures, disable security modules, unload AppArmor, read any process’s memory (including other containers), install a kernel rootkit that survives reboots, and pivot to every other workload on the host. In a multi-tenant Kubernetes cluster, this is the nightmare scenario: one compromised pod → full cluster compromise. I’ve been in incident response calls where exactly this happened. Nobody was having fun.
Why the Docker Team Was Basically Smiling When This CVE Dropped
Docker’s own documentation literally says - and I love this quote - “Three times the layers of protection there!” when describing this CVE. Because Docker blocks ptrace() in three separate, independent ways:
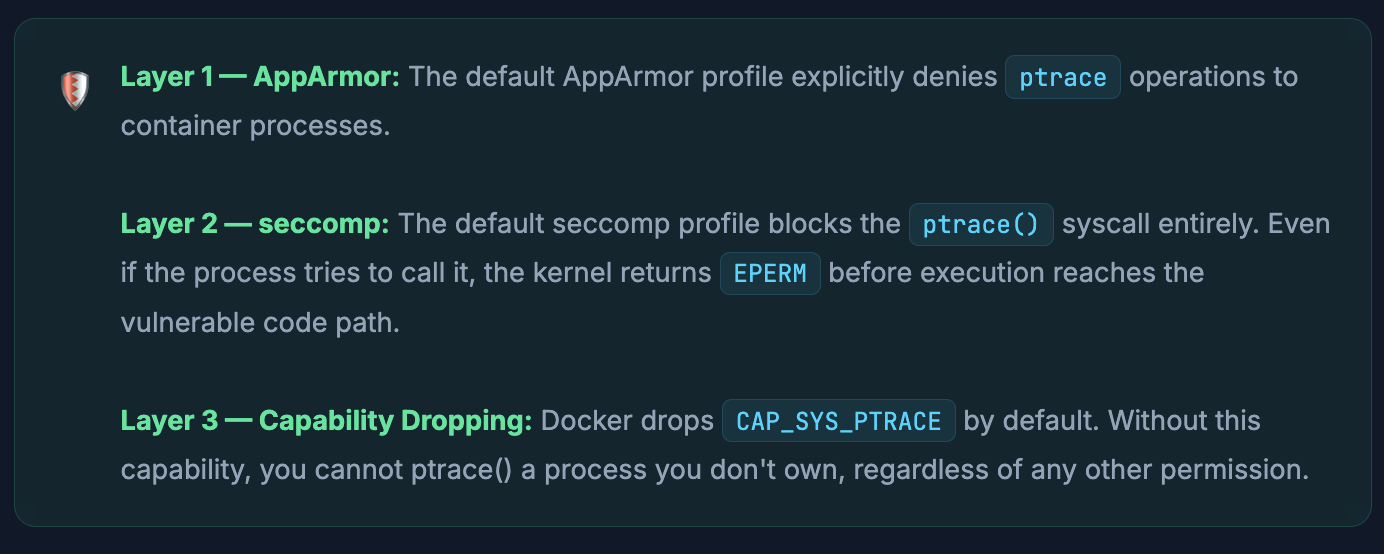
An attacker inside a Docker container would need to break through AppArmor and seccomp and the capability model simultaneously to even reach the vulnerable code. That’s not a bug chain - that’s a full architectural bypass of Docker’s security model, which is a completely different (and much harder) problem.
The real lesson here: Defense-in-depth isn't just about "more is better." It's about independent layers. If AppArmor is misconfigured or bypassed, seccomp still catches it. If someone turns off seccomp, capability dropping still blocks it. The layers aren't redundant - they're orthogonal. This is exactly why you should never disable one "because another one covers it."
What Breaks If You Enable ptrace in Containers
Some legitimate use cases require ptrace: running strace inside a container for debugging, running gdb for core dump analysis, profiling tools like perf. The standard pattern is:
# ❌ NEVER do this in production (opens all ptrace attack surface)
docker run --cap-add SYS_PTRACE --security-opt seccomp=unconfined myapp
# ✅ Correct: add capability only, keep seccomp profile
docker run --cap-add SYS_PTRACE myapp
# ✅ Even better: use a debug sidecar container, not the prod image
docker run --cap-add SYS_PTRACE --pid container:myapp-container debug-image
# In Kubernetes - only for debug pods, never in workload specs
securityContext:
capabilities:
add: ["SYS_PTRACE"] # gate this with OPA/Kyverno admission policy
CVE-2014-9529 & CVE-2016-0728: The Keyctl Chaos
What On Earth Is keyctl()?
The Linux kernel has a key management subsystem - essentially an in-kernel secure storage for cryptographic keys, authentication tokens, and other sensitive data. The keyctl() syscall is how userspace interacts with it. You might use it without knowing through Kerberos, CIFS mounts, or certain PAM modules.
CVE-2014-9529 is a nasty race condition. A series of crafted keyctl() calls - specifically requesting key operations concurrently - triggers a use-after-free in the key garbage collection code. The freed memory can be reallocated and controlled by the attacker, leading to kernel memory corruption. On many systems this is reliable enough for a privilege escalation exploit.
CVE-2016-0728 is arguably worse. It’s a use-after-free triggered by joining key sessions via keyctl(JOIN_SESSION_KEYRING) followed by careful reference count manipulation. The bug existed for 3 years before discovery. It was exploitable on every Linux kernel from 3.8 onwards - meaning essentially all Linux systems at the time. The research team that discovered it estimated tens of millions of Android devices were affected, plus all Linux servers running kernels in that range.
💀 The Blast Radius of CVE-2016-0728
When this dropped in January 2016, it hit the security community like a truck. Android, Ubuntu, RHEL, CentOS, Debian - all vulnerable. The exploitation path is local privilege escalation: any process that can call keyctl() can eventually get root. On a shared server running Docker containers without seccomp, any process in any container could escalate to root on the host OS. The container boundary means nothing here because the exploit is entirely in the kernel. The container just needs to be able to make the syscall.
Docker’s Simple Answer: Just Don’t
🛡️ Docker’s default seccomp profile blocks keyctl() entirely. Container workloads almost never legitimately need to interact with the kernel’s key management subsystem. So Docker just… doesn’t give them access. The syscall is filtered out. The exploit never reaches the vulnerable kernel code because the kernel never even receives the syscall.
🧠 The deeper principle: Docker's default seccomp profile blocks ~50 syscalls that containers don't need. Not because those syscalls are all individually dangerous, but because the attack surface reduction is massive. If an attacker inside your container can only call the ~300 syscalls that typical applications actually need, the set of kernel CVEs they can potentially exploit shrinks dramatically. When CVE-2016-0728 dropped, Docker users got to watch the chaos from the sidelines sipping coffee.
# Inside a Docker container with default seccomp
strace -e trace=keyctl keyctl show
keyctl(KEYCTL_GET_KEYRING_ID, KEY_SPEC_SESSION_KEYRING, 0) = -1
EPERM (Operation not permitted)
# ↑ seccomp filter returned EPERM before reaching kernel code
# Check what your seccomp profile is blocking
docker inspect --format '{{json .HostConfig.SecurityOpt}}' my-container
# ["seccomp=/path/to/profile.json"] or [] (default profile active)
# If you need keyctl for Kerberos/CIFS (legitimate use), be specific:
docker run --security-opt seccomp=/path/to/keyctl-allowed.json myapp
# Write a custom profile that allows only the keyctl sub-commands you need
CVE-2015-3214 & CVE-2015-4036: When Docker Is Safer Than a VM
The “VMs Are More Secure” Crowd Is Going to Hate This
I want you to really enjoy this one, because it flips the conventional wisdom upside down and throws it out the window. The standard security narrative goes: “Containers share the kernel, VMs have hardware isolation, therefore VMs are more secure.” This is… mostly true but not universally true. These CVEs are cases where containers are actually more secure than VMs.
CVE-2015-3214 is a bug in the i8253/i8254 Programmable Interval Timer (PIT) emulation in QEMU/KVM. The PIT is a real hardware component that VMs emulate - it handles timing signals for the guest OS. A bug in the boundary checking of the i8253_mem_read function allows a guest OS user to read and write out-of-bounds memory in the QEMU process (which runs on the host). This is a virtual machine escape - from inside the VM to code execution on the host.
CVE-2015-4036 is similar - a buffer overflow in the SCSI (virtio-scsi) controller emulation code. An attacker with access to the SCSI driver inside a VM can overflow a buffer in QEMU’s host-side code, again leading to host-level code execution. Game over.
💀 VM Escapes: Rarer But Catastrophic When They Hit
VM escapes hit cloud providers hard. If your EC2 instance is sharing hardware with another tenant’s instance, and a VM escape vulnerability exists, that other tenant could theoretically break out of their VM and reach yours. This is why cloud providers have dedicated teams tracking QEMU and KVM CVEs, pushing hypervisor patches with urgency typically reserved for active exploits. These aren’t theoretical - VM escapes have been demonstrated at pwn2own competitions and in the wild.
Why Docker Containers Don’t Have This Problem
Docker containers don’t emulate hardware at all. There’s no QEMU PIT emulation. There’s no virtio-scsi controller. Unless you explicitly pass through a device with --device, containers have no access to any virtualization device interfaces. The attack surface that these CVEs target simply doesn’t exist in a Docker container. You can’t overflow QEMU’s timer code if there’s no QEMU timer emulation layer to overflow.
This is genuinely one of those cases where the architectural simplicity of containers works in their favor. VMs add a whole emulation layer that creates its own attack surface. Containers skip that entirely. The Docker docs explicitly and correctly note: “containers are more secure than VMs in this case.” I love when the docs are honest like that.
😂 Next time someone in a meeting says "but VMs are more secure than containers," pull up these CVEs. Watch their face. Don't say anything. Just watch. Security is contextual - there's no universal winner. It depends on what you're protecting against. Neither VMs nor containers are universally "more secure." They have different trust boundaries and different attack surfaces.
CVE-2015-3290 & CVE-2015-5157: When the Kernel’s Panic Button Has a Bug
What Is a Non-Maskable Interrupt?
A Non-Maskable Interrupt (NMI) is a hardware interrupt that the processor cannot ignore. Unlike normal interrupts which can be deferred or disabled by software, NMIs are hardwired to be handled immediately. They’re used for hardware failure detection, watchdog timers, and debugging. The kernel’s NMI handler is one of the most privileged and timing-sensitive paths in the entire codebase.
CVE-2015-3290 is a privilege escalation in the kernel’s NMI handler on x86. The bug involves the modify_ldt() syscall - a legacy x86 call that modifies the Local Descriptor Table, affecting memory segment boundaries. When a carefully timed NMI occurs during certain modify_ldt() operations, the kernel can end up in an unexpected execution context, leading to privilege escalation.
CVE-2015-5157 is related - a nested NMI handling bug on x86_64. When an NMI occurs while the kernel is already handling another NMI (nested NMI), certain architectures handle this incorrectly, allowing kernel stack corruption and privilege escalation.
The Honest Answer: Docker Has a Gap Here
This is one of the cases where I want to be honest rather than cheerleading. Docker’s documentation explicitly acknowledges that these CVEs can be exploited in Docker containers because modify_ldt() is not blocked in the default seccomp profile.
Partial protection only. There is no blocking of modify_ldt() by default in Docker’s seccomp profile. Docker acknowledges this is an open gap. The reason it hasn’t been blocked: modify_ldt() has some legitimate uses in older x86 applications (32-bit Wine, some Java versions on old kernels). Blocking it would break backward compatibility for those workloads.
🚨 If you're running untrusted workloads or a container-as-a-service platform, you should consider explicitly blocking modify_ldt() in a custom seccomp profile. The vast majority of modern containerized applications have no need for this syscall. The CVEs above are the specific reason some high-security container runtimes (like gVisor) block it by default. This is one of the entries in the non-events list that isn't fully a "non-event" - it's "event with caveats."
# Start from Docker's default profile and add modify_ldt to blocklist
# Download default: https://github.com/moby/moby/blob/master/profiles/seccomp/default.json
# Add to the "syscalls" array under "action": "SCMP_ACT_ERRNO"
{
"names": ["modify_ldt"],
"action": "SCMP_ACT_ERRNO",
"errnoRet": 1 // EPERM
}
# Apply to your containers
docker run --security-opt seccomp=/path/to/hardened-profile.json myapp
# Or in Docker Compose
security_opt:
- seccomp:/path/to/hardened-profile.json
CVE-2016-2383: eBPF Reads Your Kernel Memory (Ironically Blocked by Seccomp)
Some Context on eBPF First
eBPF (extended Berkeley Packet Filter) is one of the most powerful features of the modern Linux kernel. It’s a virtual machine inside the kernel that lets you run sandboxed programs in response to kernel events - for tracing, networking, security monitoring, you name it. Tools like Cilium, Falco, and Tetragon are built on eBPF. It’s genuinely amazing technology.
It’s also, historically, a significant attack surface. The eBPF verifier the component that’s supposed to ensure eBPF programs can’t do dangerous things - has had multiple serious bugs over the years. CVE-2016-2383 is the first major one.
The Bug: Off-by-One in the eBPF JIT
The eBPF JIT (Just-In-Time) compiler translates eBPF bytecode into native machine instructions for performance. CVE-2016-2383 is an incorrect branch offset calculation in the JIT for the BPF_JNE (jump-not-equal) instruction. When the kernel JIT-compiles certain eBPF programs, the generated machine code jumps to the wrong address. With a carefully crafted eBPF program, an attacker can use this to trigger jumps into attacker-controlled memory patterns, leading to arbitrary kernel memory reads.
Arbitrary kernel memory read is extremely dangerous: it lets you dump kernel address space, extract kernel pointers (defeating KASLR), read other processes’ memory including cryptographic keys, and gather information needed for deeper exploitation. It’s the reconnaissance phase of a kernel takeover.
💀 What An Attacker Does With Kernel Memory Reads
Modern kernels use KASLR (Kernel Address Space Layout Randomization) to make it harder to exploit memory corruption bugs - you need to know where things are in memory before you can overwrite them. Arbitrary kernel reads bypass KASLR completely. Once you have the kernel’s base address, every other memory corruption vulnerability becomes trivially exploitable. A container escape that was previously “theoretical” becomes a working exploit chain. This is why info-leak bugs often have critical severity despite not directly causing code execution.
The Beautiful Irony
The bpf() syscall is blocked inside Docker containers using seccomp. And what is seccomp? It's a eBPF-based syscall filter. So: eBPF's seccomp interface blocks the bpf() syscall, which prevents exploitation of the eBPF JIT vulnerability. eBPF is protecting you from eBPF. The Docker documentation literally calls this out as ironic, and they're right. I love this job sometimes.
🔮
Modern context: eBPF has become a cornerstone of Kubernetes observability and security tooling (Cilium, Tetragon, Falco eBPF mode, etc.). These tools often run in privileged containers or with CAP_BPF. If your security tools require elevated eBPF privileges, make sure you understand what that unlocks. CVE-2016-2383 was the first - there have been several more eBPF verifier bugs since (CVE-2021-3490 being particularly nasty). Your monitoring stack is part of your attack surface.
CVE-2016-3134, CVE-2016-4997, CVE-2016-4998: Netfilter Corruption
What Is Netfilter?
Netfilter is the Linux kernel’s packet filtering framework - the engine behind iptables, nftables, and ipset. When you set firewall rules, route packets between containers, or configure NAT, Netfilter is doing the actual work in the kernel. It’s used by Docker itself to manage container networking.
The interface to configure Netfilter from userspace goes through setsockopt() with options like IPT_SO_SET_REPLACE, ARPT_SO_SET_REPLACE, and ARPT_SO_SET_ADD_COUNTERS. These are how tools like iptables install rules into the kernel.
The Bugs: Memory Corruption Through Table Replacement
CVE-2016-3134: When replacing an entire iptables table via IPT_SO_SET_REPLACE, the kernel fails to validate that the entry sizes in the user-supplied table are consistent with the total table size. An attacker can supply a malformed table where the entry counts don’t match the actual data size, causing the kernel to read or write memory beyond the allocated buffer. Classic heap overflow leading to privilege escalation.
CVE-2016-4997 and CVE-2016-4998 are variants affecting the ARP tables (arptables) with the same class of validation failures - heap corruption through the ARPT_SO_SET_REPLACE and ARPT_SO_SET_ADD_COUNTERS options.
💀 Combining This With Network-Aware Containers The particularly nasty scenario: you're running a container that handles network configuration - maybe a service mesh sidecar, an SDN controller, or a container that manages iptables rules for your application. If that container is compromised and has the wrong capabilities, the attacker can use these setsockopt bugs to corrupt the host kernel's memory. They're already in a network-privileged context, which makes the attack even more natural. One misconfigured pod in your Kubernetes cluster becomes the launchpad for a host compromise.
Why Docker Is Clean Here: CAP_NET_ADMIN
These setsockopt options require CAP_NET_ADMIN. Docker does not grant CAP_NET_ADMIN to containers by default. Without this capability, the IPT_SO_SET_REPLACE and related options simply return EPERM. The vulnerable kernel code path is never reached. You'd have to explicitly --cap-add NET_ADMIN to expose this attack surface.
This is why CAP_NET_ADMIN is not a “harmless” capability. I’ve seen teams add it to fix networking issues (“the container needs to set routes”) without realizing they’re also enabling iptables manipulation and a class of kernel exploitation that includes these CVEs. Every capability you add should be documented, justified, and reviewed in a security context. --cap-add NET_ADMIN in a production workload should raise an immediate flag in your threat model.
CVE-2016-5195: Dirty COW - The Bug With a Logo, a Website, and Very Real Victims
A Bug So Old It Predates the iPhone
Let me start with the fun fact: Dirty COW (Copy-On-Write) was introduced into the Linux kernel in 2005. 2005. It sat there, exploitable, in every Linux kernel for eleven years before anyone found and reported it. It was patched in October 2016. The researcher who found it, Phil Oester, noted he’d seen it actively exploited in the wild on a server he was administering - meaning bad actors had already found it before the security community did.
The Technical Details: Race Condition in Memory Mapping
Linux uses a technique called Copy-on-Write (COW) for memory efficiency. When two processes share read-only memory (like a shared library), the kernel only makes a private copy when one process tries to write to it - hence “copy on write.” This saves memory for the common case where no writes happen.
Dirty COW is a race condition in this mechanism. When a process uses madvise(MADV_DONTNEED) to race against a concurrent write to a private COW mapping via /proc/self/mem or ptrace(PTRACE_POKEDATA), the kernel can be tricked into writing to a read-only memory-mapped file on disk - bypassing all filesystem permission checks. You can write to files you don’t have write permission for. Including /etc/passwd. Including any setuid binary. Including anything.
💀 What Eleven Years of Exploitation Looks Like Dirty COW was used to: escalate privileges on millions of Android devices (ZNIU malware, which stole money from over 1200 users across 40 countries using Dirty COW); escape Docker containers in misconfigured environments where /proc/self/mem was accessible; gain root on shared hosting servers; modify SUID binaries to install persistent root backdoors. The CVE score of 7.8 actually undersells the impact because it only rates it as "local privilege escalation" - but in containerized environments, local = container = potentially the entire cluster.
Where Docker’s Mitigation Holds (And Where It Doesn’t)
Docker’s docs say this has a “partial mitigation” - and they’re being accurate. Let’s break down exactly what is and isn’t protected:
Protected path: The primary Dirty COW exploitation path requires ptrace(PTRACE_POKEDATA) or access to /proc/self/mem with write permissions. Docker blocks ptrace() via seccomp (as discussed in CVE-2014-4699). On many distros, /proc/self/mem is mounted read-only inside containers. These together block the most common exploitation paths.
Unprotected path: Not all distros mount /proc/self/mem as read-only. If your host OS doesn’t do this, and seccomp is disabled (or the madvise-based variant is used, which doesn’t require ptrace), the exploit can still work from inside a container. The actual fix for Dirty COW is to patch the kernel. There is no Docker-level mitigation that fully protects against all exploitation variants. If you were still running an unpatched kernel in late 2016, Docker was providing partial protection, not complete protection.
# Check kernel version (should be >= 4.8.3, or distro-patched)
uname -r
# 5.15.0-xxx ← any modern kernel is patched
# Check if /proc/self/mem is write-protected inside container
docker run --rm ubuntu bash -c \
"ls -la /proc/self/mem"
# -rw------- 1 root root ← should be readable only by owner
# More importantly: cat /proc/self/mountinfo | grep proc
# Additional check: verify seccomp is active
docker run --rm ubuntu \
grep -i seccomp /proc/1/status
# Seccomp: 2 ← 2 = SECCOMP_MODE_FILTER (active)
# Seccomp: 0 ← 0 = disabled. Fix this immediately.
🔑 The Most Important Field Lesson Dirty COW is the definitive proof that kernel patching and container security hardening are not alternatives - they are complementary. Docker's mitigations buy you time and reduce your attack surface, but they are not a substitute for a patched kernel. The single most impactful security action you can take for your containerized workloads is running a current, patched kernel. Docker's hardening is the belt. Kernel patches are the suspenders. Wear both.
Production Hardening: What I Actually Do After a Decade of Pain
Reading about CVEs is educational. Actually getting paged at 3am because one of these bit you is educational in a different way - the way that makes you obsessively paranoid about security for the rest of your career. Here’s what I’ve learned translates to real, production-grade hardening:
The Five Commandments of Container Security
✅ Never run as root in production containers. I cannot stress this enough. If your Dockerfile ends with USER root, that’s a bug, not a configuration. Run as UID 1000+. Set it in the Dockerfile and lock it in the Kubernetes PodSecurityContext. This single change eliminates half the attack surface discussed in this post.
✅ Default seccomp profile is not optional. Don’t run with --security-opt seccomp=unconfined in production. Ever. Not even “just temporarily.” Temporary configurations have a remarkably long half-life in infrastructure. If a tool requires a specific syscall, write a custom seccomp profile that allows only that syscall. This is an hour of work that prevents years of regret.
✅ Capability audit every quarter. List every container in production that has --cap-add anything. For each one, verify why it needs that capability. CAP_NET_ADMIN, CAP_SYS_ADMIN, CAP_SYS_PTRACE, CAP_SYS_MODULE - these are your highest-risk additions. Build an automated check into your CI pipeline that fails the build if unexpected capabilities are added to production workloads.
✅ Patch the kernel, not just the containers. Dirty COW taught everyone this lesson. Your container images can be perfectly hardened and you can still get owned via a kernel vulnerability if the host is running a kernel from 2018. Implement automated kernel patching. Yes, this requires reboots. Yes, reboots require availability planning. That’s the job.
✅ Use AppArmor or SELinux - not instead of seccomp, in addition to it. These are orthogonal protection mechanisms. AppArmor adds file-level access control on top of the capability model. seccomp adds syscall-level filtering. The CVEs in this post were stopped by different mechanisms - there is genuine defense depth value in having both active simultaneously.
The Things I Stopped Doing (So You Don’t Have To Learn the Hard Way)
✗ Running the Docker socket in containers. Mounting /var/run/docker.sock into a container is functionally giving that container root on the host. The entire CVE history of Docker becomes irrelevant - you’ve already given up the keys. If you need Docker-in-Docker, use rootless Docker or the --userns-remap option.
✗ Pulling base images without digest pinning. FROM ubuntu:latest in production is an invitation for supply chain attacks. Use digest pinning: FROM ubuntu@sha256:abc123.... Your images should be reproducible and auditable.
✗ Privileged containers for anything that isn’t genuinely system-level. Teams add --privileged to “fix something” and never remove it. A privileged container defeats essentially every mitigation discussed in this post. It disables seccomp, drops capability restrictions, and gives the container full host access. Treat it like root shell access to your servers - because that’s what it is.
Production Hardening Checklist
# Pod-level security context
spec:
securityContext:
runAsNonRoot: true # CVE-2014-0181, 2015-3339 mitigation
runAsUser: 1000
runAsGroup: 1000
fsGroup: 1000
seccompProfile:
type: RuntimeDefault # enables default seccomp - blocks keyctl, bpf, etc
containers:
- name: myapp
securityContext:
allowPrivilegeEscalation: false # NO_NEW_PRIVS
readOnlyRootFilesystem: true
capabilities:
drop: ["ALL"] # drop everything first
add: [] # add back only what you explicitly need
# NEVER add these without a documented, security-reviewed justification:
# SYS_ADMIN, SYS_PTRACE, SYS_MODULE, NET_ADMIN, SYS_RAWIO
# Enforce via Kyverno policy (catches it at admission time)
apiVersion: kyverno.io/v1
kind: ClusterPolicy
spec:
rules:
- name: require-non-root
match:
resources: { kinds: ["Pod"] }
validate:
pattern:
spec:
securityContext:
runAsNonRoot: true
The Big Picture: Security Architecture Over Reactive Patching
Here’s what this entire non-events list is actually saying, if you read between the lines:
Docker’s security team didn’t know about Dirty COW in 2013. They didn’t know about the keyctl use-after-free when they designed the seccomp profile. They didn’t know about the eBPF JIT bug when they blocked the bpf() syscall. What they did was implement a principled security architecture - defense-in-depth, least privilege, attack surface reduction, capability dropping - and then those principled decisions happened to block vulnerabilities that were discovered years later.
That’s the actual lesson. Reactive security - patching CVEs as they drop - is table stakes. You have to do it. But the organizations that never get breached aren’t the ones with the fastest patch cadence. They’re the ones that made architectural decisions that minimized the blast radius of vulnerabilities they hadn’t discovered yet.
The non-events list is proof that security architecture works. Not perfectly - see the NMI handling and Dirty COW caveats - but remarkably well for a list of CVEs that span a decade of kernel development across attack categories that didn’t exist when Docker’s security model was designed.
Thanks If you made it to the end of this post: you're the engineer your team needs. Most people see a CVE, check if they're on an affected version, and move on. You're here understanding why the mitigation works and where it has gaps. That's the difference between security hygiene and security engineering. Enjoy a well-deserved beverage. Then go audit your production seccomp profiles, because there's definitely a seccomp=unconfined in there somewhere. I believe in you.

Comments (0)
No comments yet. Be the first to share your thoughts.
Leave a comment